

继《》、《》、《》之后,知名 Linux 内核一线开采者,经典册本《Linux 建造驱动开采详解》作家宋宝华素养又给各人带来了 2025 年 Linux 内核开采中,十个最典型的patchset,为各人呈现干货满满的硬核时期年货。
作家 | 宋宝华 责编 | 张红月
出品 | CSDN(ID:CSDNnews)
从未来起,作念一个幸福的东谈主。喂马,劈柴,周游宇宙。从未来起,暖热食粮和蔬菜。我有一所屋子,面朝大海,百鸟争鸣。 ——海子《面朝大海,百鸟争鸣》
2026 农历新年的钟声行将敲响,在这全球共庆的跨年时刻,Linux 内核年度十大时期立异清点如约而至。
回望已往的一年,往常的日子里夹杂着些许苦涩与无奈。每一个微小的个体,不管心中藏着怎样的追到或昂然,皆让它随风而去吧。新的一年里,纵令现实仍有诸多敛迹,也愿各位心底决然面朝大海,百鸟争鸣。
已往的一年,内核开采者们日旰忘食地千里浸在代码的纵情宇宙中,不停提交patch,股东 Linux 内核前行。
本文将清点其中最具代表性的十个 patchset:
1
slab per-CPU cache机制:Sheaves(一捆)和barns(谷仓)
2
sched_ext: cgroup sub-scheduler支抓
3
代理奉行proxy-execution以科罚优先级翻转
4
swap table替代xarray
5
TCP零拷贝发送DMABUF
6
调度器时分片膨胀time slice extension
7
multi-kernel
8
io_uring的积贮零拷贝收包
9
io_uring dmabuf读写支抓
10
dmem cgroup
底下逐个张开刻画。

slab per-CPU cache 机制:Sheaves(一捆)和barns(谷仓)
内存料理的 buddy 是有 pcp(Per-CPU Page frame cache) 的,针对 buddy 肯求和开释的内存,治愈一定量的 Per-CPU 的 free 内存 list,以减小每次皆从底层 buddy 获取、开释 pages 的锁竞争:

对于 Linux 内核 kmalloc/kfree 底层的 slab,试验上咱们也需要访佛的 per-CPU 机制,来减小 object 肯求和开释时候跨 CPU 的锁竞争和跨 CPU 的 cache 同步等支出。Vlastimil Babka 的 patchset,把“农场”的 Sheaves 和 Barns 认识借用到内核中,以支抓 slab 的 per-CPU cache 才气。

(图源:https://www.reddit.com/r//comments/1nd8hav/what_that_means/)
Sheaves(束/捆)
字面兴味是“麦束”或“一捆”,内核中指每个 CPU 土产货的一小批 slab object缓存,用于加速土产货分派/开释,减少锁竞争。是一种per‑CPU 对象缓存,用来快速恬逸分派和开释请求。每个 CPU 治愈两个小缓存(主 sheaf 和备用 sheaf),只须其中有对象,就成功复返/放回,无须去拜访全局 slab 页或锁住别东谈主,从而提高性能。分派/开释 object 大多数情况下是土产货、无锁的操作。
Barns(谷仓/仓库)
字面兴味是“谷仓”或“仓库”,内核中指全局 slab 池(然则是按照NUMA来料理的),供各个 CPU 的 sheaves 补充或回收,其功能是保证全局内存均衡,处理 sheaves 空或满的情况。barn 里有两类部队:full(装满对象的 sheaf)和empty(空 sheaf),方便快速交换。
当某个 CPU 的 sheaves满了或空了时,才波及到barn(谷仓):
空 sheaves:淌若分派时 sheaves 空了,CPU 会尝试从barn取一个 full sheaf。
满 sheaves:开释时 sheaves 皆满了,会往 barn 里放一个 full sheaf 或把 sheaf 里的对象回写 slab 页面。


sched_ext: cgroup sub-scheduler 支抓
这个 patchset 来自 Tejun Heo,为 sched_ext 增多了基于 cgroup 的子调度器(sub-scheduler)支抓,使多个 BPF 调度器不错按 cgroup 层级结构协同最先:父调度器负责在不同 cgroup(佃户/分区)之间分派 CPU 资源,子调度器负责各自 cgroup 里面的任务调度。这么系统就能按 workload 分区部署不同调度计策,恬逸多佃户奇迹器和混部场景下对互异化调度(如延伸优先、迷糊优先等)的需求。比如不同的业务类型需求不相似,不错构成如基档次化的调度系统:

上图中,数据库系统的调度器能够明白查询的优先级和锁抓有者的蹙迫性(criticality)。编造机料理要津(VMM)不错与编造机里面的调度器协同,并智能地安排 vCPU 的位置。游戏引擎的调度器则知谈渲染的截止时分,以及哪些线程对延伸明锐(latency-critical)。
每个 cgroup 可绑定一个 scheduler,父 scheduler 通过 dispatch 驱动子 scheduler 得回 CPU 时分,从而形成自顶向下的带宽分派 + 组内调度两级(或多级)结构,咫尺适度最大深度SCX_SUB_MAX_DEPTH = 4,刺眼调度旅途过深、复杂度失控。
父 scheduler 在ops.dispatch()里面决定哪个子 scheduler 最先以及给几许 CPU 时分。每个 sub-scheduler 皆是沉寂实例,治愈我方的最先参数,典型包括:默许时分片(time slice)、watchdog(卡死检测)、bypass mode(旁路口头)、土产货 DSQ / runqueue 状况,因此,每个 cgroup可能成为一个沉寂调度域。父 scheduler的ops.dispatch()不错调用scx_bpf_sub_dispatch()来触发子调度器的 dispatch,child 再选具体 task 最先。
tj 的 patchset 一共 34 个 patch:


代理奉行 proxy-execution 以科罚优先级翻转
如下图,P2 求 P1 的抓有的锁,然则 P1 因为被霸占(时分片花消等原因)拿不到 CPU,从而 P2 要等很久才拿到锁,变成用户层面的卡顿体验。

代理奉行的逻辑是,在调度层面把调度高下文和奉行高下文分开。假定 P2 高下求锁而不得的时候,它会在它的 task_struct 里面纪录 block_on 什么任务上头,在这里是 P1,于是 P2 会把我方的时分(调度高下文)“捐献”给 P1 去跑,P1 用 P2 捐献给我方的时分奉行 P1 的代码(奉行高下文)。
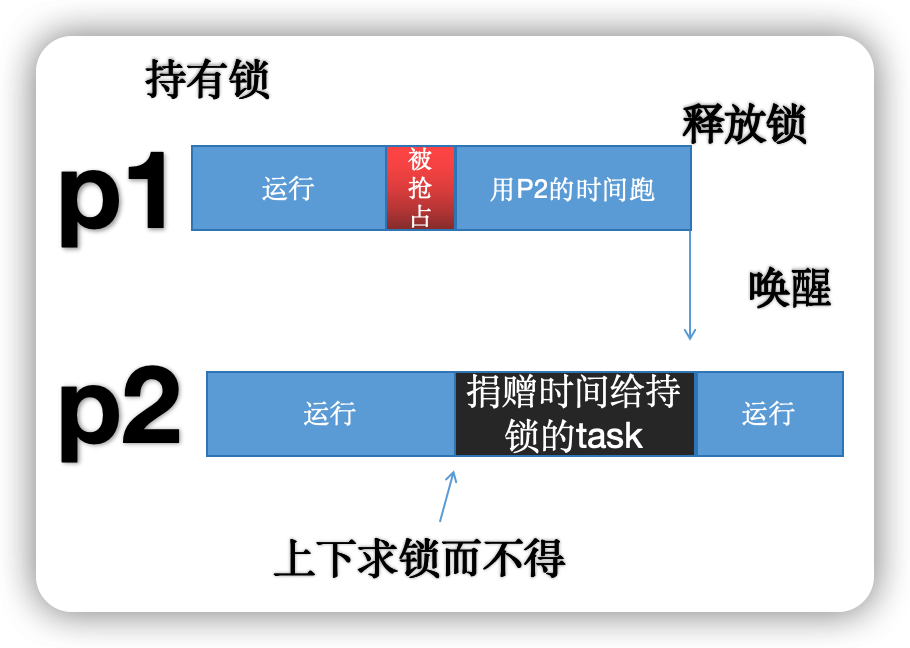
如上图所示,咫尺 P2 把时分捐给 P1 后,很快 P1 就把锁开释了。关联词,妖魔皆在细节里,试验上,这里面有一些复杂的问题:
1. P2 把时分捐给 P1 后,P1 最先的过程中说不定会条款抓有第 2 个锁恭候,因此再次梗阻;显然咱们需要把这个捐赠的过程变成一个链条。
2. P1 和 P2 可能不在一个 CPU 上,不在一个 runqueue 上头,跨国没法捐。是以咱们很可能要把 P2 的调度高下文先迁徙到 P1 上头去给 P1。
咫尺 6.17 合入的是一个 baby step,支抓 P1 和 P2 本人在一个 CPU 上的时候的代理奉行,咫尺显然莫得试验兴味兴味,因为哪怕手机独一 8 个核,P1 和 P2 在合并个 CPU 的契机也很飘渺。然则,基于社区迭代开采的经过兴味兴味上来讲,这是极其首要的一个进展,它为 proxy execution 的将来开启了一扇大门。 对于 Donor Migration 的支抓,已成为一个单独的 patchset 来开采和 review。
proxy execution 主要由 Google 的 John Stultz 指导开采,由多名 developer 合伙孝敬,其首要主义在于改善 Android 系统的用户体验。


swap table 替代 xarray
swap table 本色上是一种替代咫尺 xarray 料理样式的,更精辟、更高性能的 swapcache 完了。
在 Linux 内核中,咱们用 xarray 来刻画一个文献的 pagecache 掷中情况。比如一个很大的文献,在 pagecache 中只掷中了很少的页。拿到相应位置的文献 offset,则可通过 xarray 树形结构的逐级查询(访佛多级页表从编造地址到物理地址的样式)来获知这些掷中页的指针,而其他绝大多数区间由于未在 pagecache 掷中,并不需要在 xarray 上分派出元数据。

在 Linux 内核的完了中,针对匿名页,也存在一种与文献页的 pagecache 访佛的东西,叫 swapcache。swapcache 可简略明白为一张表,给到一个 offset,不错查询到对应 swap slot,是否在内存也有副本,淌若有,副本是哪一个 page。

在 swapcache 的料理上,Linux 内核接受了与文献页 page cache 料理相似的作念法,以致底层 swapcache 的查询 API 皆波折是文献的 API:

咫尺 Linux 内核把 swap 分区/文献的每 64MB 组织为一个 address_space,每 64MB 动作 1 个 xarray 来刻画。

swap 相对文献其实是有显贵区别的:
1. swap 分区/文献的数目是相对有限的,通常即是 1 个,常见的设立也很难突出 4、5 个。不像文献,可能千千万万无数个。
2. swap 的大小相对来说是固定的,可测度的。比如开机设立好了,就基本不动了。 不像文献,有大有小,大则几许个 T,小则几许个 B,丰富多采。
3. swap 的拜访模子相对可控,针对特定的 workload 场景,有几许 swap 空间会被用到,相对来说是可测度的。
这为 swapcache 的至简化联想创造了可能性, swap table 的联想和完了出身了 。
假定一个swap分区是 2GB,咱们先把这 2GB swap 空间按照 2MB 拆分为cluster:

而每个 cluster 里面则有 512 个 swap slot。

swap table 的联想理念荒谬简略,它为每个 cluster 给出 512 个 unsigned long 型数据,这个 unsigned long 数据不错存放 swapcache 掷中的 page(咫尺咱们或可别扭地名称它为“folio”)的指针,或者是 shadow(用于 refault 机制),真钱投注app平台或者是 NULL。
}
这么,对于 64 位的 arm64, x86_64 等 arch 而言,每个 cluster 的 swap table 占据的内存恰巧是 4KB。
字据 swap offset,咱们通过它的高位不错找到它属于哪个 cluster,而通过它的低位不错找到它对应 512 个 slot 里面的哪一个 slot:
}
由此可见,这个检索过程是相对于 xarray 而言是更快的,相对于 xarray 原先的 O(logN),咫尺可觉得是 O(1)。原先 swapcache 固然限制了每个 address_space 的大小为 64MB,然则树的深度如故不错达到 3 级的。
另外,由于一个 cluster 的 swap table 的内存皆聚合在合并个 page 里面,当 swap out 密集发生在合并个 cluster 的时候,它能发挥出更强的 locality 局部性,有哄骗减小 cache miss 等。xarray 的树形结构以及基于 slab 的内存料理样式,则更可能在多个 page 里面来往进步拜访。
xarray 的树料理一个更浩荡的规模,每个 address_space 为 64MB,这意味着,会跨越多个 cluster,64MB 的规模需要妥洽料理和加锁,况且 cluster 里面的拜访也需要 cluster lock。而 swap table,本人不会垮 cluster,仅在一个 cluster 里面拜访,只需要对 2MB 的 cluster 本人加锁。由此去掉了原先料理 xarray 树形结构的锁需求。
终末,大路至简,swap table 这种访佛数组的联想念念路,写出来的代码东谈主东谈主皆能看得懂。
对于 swap table 内存占用方面的优化,在[PATCH 8/9] mm, swap: implement dynamic allocation of swap table 中,Chris 和 Kairui 试验安排了 swap table 的动态开释,在一个 cluster 里面的 512 个 slot 皆没东谈主用的时候,这个 cluster 的 swap table 不错开释。
由于 swap table 的显贵上风开首于查询旅途的裁汰、locality 的擢升、lock contention 的减小,相对 xarray 加速了 swapcache 的查询、修改等操作,属于基础设施的改善,其上风在奇迹器等场景会呈现较大的实用价值,对一些要害业务的迷糊量带来擢升。

TCP 零拷贝发送 DMABUF
Device Memory TCP (devmem TCP)完成了 2 个谋划:
通过积贮发送建造 memory。底层的建造 memory 接受 dma-buf 机制;
通过积贮继承建造 memory 并成功存入土产货的建造 memory。
因此,它是一种 Direct-to-device 的积贮门径。
咱们知谈 dma-buf 提供了一种本机里面建造与建造、建造与建造分享内存的门径,之前笔者也曾在《)》中有论说。简略地来说,dma_buf 不错完了 buffer 在多个建造的分享,应用不错把一派底层驱动 A 的 buffer 导出到用户空间成为一个 fd,也不错把 fd 导入到底层驱动 B。天然,淌若进行 mmap() 得到编造地址,CPU 亦然不错在用户空间拜访到也曾得回用户空间编造地址的底层 buffer 的。

devmem TCP 试验上把 dma-buf 的传输膨胀到积贮上并非本机的建造、CPU 之间了。由于是 A 机器的 dma-buf 送到 B 机器的 dma-buf,这么幸免了建造的 dma-buf 和 host buffer 之间的拷贝。

跨节点的 device 到 device 的传输,不才面的一些应用场景中可能受益:
散布式试验,即在不同主机上的机器学习加速器(如GPU)之间交换数据。
散布式 raw block storage 应用与良友 SSD 传输多半数据。其中大部分数据不需要主机处理。
联系的 patchset 主要由 Google 的 Mina Almasry 完成,Linux 6.12 中支抓了 rx,而 6.16 内核中,也支抓了 TCP dmabuf 的 tx 旅途。继承端的网卡应支抓 header 的自动分辨,况且支抓 flow steering 、RSS,确保谋划是 devmem 的积贮包能流向正确的 RX queue。

调度器时分片膨胀 time slice extension
想象用户态的线程 A 拿到了 spinlock,由于用户态 spinlock 并不会像内核态 spinlock 那样辞让霸占,十足有可能线程 B 霸占线程 A,线程 B 可能最先很久,而假定线程 C 需要恭候线程 A 的 spinlock 开释,这个 C 的恭候可能口角常长的。

淌若咱们提供一个机制,比如线程 A 拿到了 spinlock,在 critical section 里面奉行的过程中,若发生时分片用完或者其他什么事情要霸占 A,调度器不错膨胀少量点时分片给 A,比如 50 好意思妙内让 A 不被霸占,则线程 A 约略率不错奉行完 critical section,从而笼罩一系列问题。而具体膨胀时分片的长度则可由新增的 rseq_slice_extension_nsec 这个 sysctl 决定。
用户空间线程通过 prctl() 显式地告诉内核,它需要时分片膨胀:
prctl(PR_RSEQ_SLICE_EXTENSION, PR_RSEQ_SLICE_EXTENSION_SET, + PR_RSEQ_SLICE_EXT_ENABLE, 0, 0);
有一个 per-cpu 的 Restartable sequences(简称rseq)供用户态和内核态交互,需要时分片膨胀的一个典型的用户态伪代码如下:

淌若线程通过 prctl() 启用了该机制,就不错把 rseq::slice_ctrl::request 设为 1 来请求延长刻下时分片。当线程被中断且内核因此产生从头调度请求时,内核看到了用户态确立了 rseq::slice_ctrl::request =1,它可能选拔不立即把线程换下 CPU,而是批准一次 rseq_slice_extension_nsec 时分片膨胀并成功复返用户态接续奉行。
当内核容或时分片膨胀时,会把 rseq::slice_ctrl::request 清零,并将 rseq::slice_ctrl::granted 置为 1,暗意膨胀已批准;淌若在膨胀之后线程仍然被resched(被换下 CPU),内核会再把 granted 位清零,用来示知用户态此次膨胀也曾收尾或失效。
基于 RSEQ 的时分片膨胀使命,主要由 Thomas Gleixner 和 Peter Zijlstra 完成。

multi-kernel
Cong Wang 在 LKML 发送了一个 RFC 序列,支抓 multi-kernel。multi-kernel 与容器、hypervisor 皆有本色不同,它在合并台机器上并行最先多个 Linux kernel,每个 kernel 独占一部分硬件,并通过音书通讯协调。

在 Cong Wang 提议的门径中,host kernel 料理 spawn kernel。
Host kernel 负责:硬件资源料理、创建 / 松手子 kernel、跨 kernel 协调。Spawn kernel 负责跑应用、具备沉寂调度 / 内存 / IO 并与其他 kernel 破损。Cong Wang 的 multi-kernel 完了不错笼统为:
用 kexec 在同机启动多个 Linux
用 CPU / 内存 / IO 硬件分区作念破损
用 IPI + 分享内存通讯
用 hotplug + DT overlay 动态调资源
用硬件 queue 切分 IO
每 workload 跑定制 kernel
这个 multi-kernel 决策将来会走向何方、能否在 Linux 内核上游社区引起裕如关注和插足,皆会是很值得不雅察的看点。

io_uring 的积贮零拷贝收包
由 Pavel Begunkov 和 David Wei 完成的使命,风雅合入 Linux 内核 6.15,为 io_uring 增多了零拷贝继承(zero-copy receive)支抓,使数据能够成功批量、快速地继承并写入应用要津内存,而无需再从内核内存中拷贝一份。
io_uring 的零拷贝与 DPDK 有很大不同,DPDK 十足 bypass 了内核,而 io_uring 这种内核为 userspace 提供的 async I/O 口头,则仍然重用了内核的积贮机制,如下图,鉴戒硬件的支抓,payload 被硬件成功 DMA 到 userspace 的 buffers。

io_uring 提供了一种“羼杂旁路(hybrid bypass)”机制:在保抓与 Linux 内核体系细致集成的同期,完了了显贵的性能擢升。比较 DPDK 这种十足旁路(full bypass)决策,它在使用上愈加浅易,对现有系统的侵入性也更低。
它的系数使命经过如下:

在 io_uring中,用户和内核通过 2 个 queue 交互:SQ(Submission Queue)、CQ(Completion Queue)。

由于 DMA 要成功往 userspace 的 buffers 里面传输数据,是以 buffer 需要在内核 pin 住,联系 API 是:io_uring_register_buffers()。
与前边的 devmem TCP 相似,该机制也依赖于硬件的报文头/数据分辨(header/data split)、流量指导(flow steering)以及 RSS(继承端膨胀),以确保数据包头部保留在内核内存中,而独一谋划流量才会被导向设立为零拷贝的硬件继承部队。

io_uring dmabuf 读写支抓
这个 patchset 试图让存储建造(如 NVMe)不错成功 DMA 到 dmabuf 所代表的内存,而不是走用户页缓存 / copy 旅途。
用户态发起:
{ dma_buf_fd, file_fd });即:
提供 dmabuf fd
提供谋划 file fd(如 nvme block)
发起读:
io_uring_prep_read_fixed(..., reg_buf_idx);
慎重这套才气不是给通用文献 I/O 准备的,而是给高性能数据管线 / 建造纵贯 pipeline 用的,不是 ext4 / f2fs 等文献读写。
该 patchset 把 dmabuf 封装成一种可被 block 层提交和 DMA 的 buffer 类型,让存储建造不错成功对 dmabuf 作念 DMA。主要完了旨趣(4 步):
A.注册:dmabuf → dma_token
用户用 dmabuf fd 注册 io_uring buffer 时:
dma_buf_get()
dma_buf_attach(target_device)
dma_buf_map_attachment()
→ stable
然后封装成一个里靠近象:dma_token,它代表一块可 DMA 的分享内存。
B. 提交 IO:新 iterator 类型
新增一种 buffer 迭代器:ITER_DMA_TOKEN
提交 read/write 时:
SQE → dma_token → iov_iter
让 block 层识别这是 dmabuf,而不是用户页。
C. 构建 bio / request
block 层纠正后不错:
bio → dma_token → sg_table
不再依赖 page,而是成功用 dmabuf 的 scatter-gather 表。
D. Driver DMA
以 NVMe 为例:
sg_table → PRP / SGL → device DMA → dmabuf
完了有储建造成功 DMA 到 dmabuf 内存。

dmem cgroup
在较早的内核中,cgroup 也曾不错料理普通系统内存(RSS、swap 等),但短缺针对 GPU / 加速器建造内存的妥洽计量与限制机制。
dmem cgroup 是用来对“建造专有内存(device memory)”作念资源破损与计量的 cgroup 适度器。它管的不是普通 DRAM,而是 GPU、accelerator 和其他的 device 土产货内存。dmem cgroup 主义在于:
让 cgroup 能统计建造内存使用量;
能针对这些内存确立 min/low/max 限制;
能在资源过度使用时作念 eviction(回收/终结)
在 Linux 6.14 中,DMEM cgroup 支抓也曾集成到 Intel Xe 内核图形驱动中,用于字据 cgroup 层级限制显存(vRAM)的使用。这个用于显存内存计数的 DMEM cgroup 代码,也不错“沉静地”被其他依赖 TTM(Translation Table Maps)进行内存料理的内核图形驱动复用。
dmem 的 cgroup 接口如下:
dmem.current:刻下 cgroup 使用的 device memory 字节数;
dmem.max, dmem.min, dmem.low: nested-keyed(支抓层级键值),用于设立不同 cgroup 的内存资源限制;
dmem.capacity:走漏该内存区域的最大容量,仅存在于 root。
dmem 的系数完了旨趣如下:

作家简介
宋宝华,经典念书《Linux建造驱动开采详解》作家。Linux 干线内核dma-mapping benchmark、SWAP、THP 的治愈者或审核者,累计给 Linux 干线内核孝敬数百个补丁。在 Linux 调度器、内存料理、ARM arch、DMA、中断、驱动等规模有往常的孝敬,是 SCHED_CLUSTER、PER_NUMA CMA、zswap 硬件压缩解压、ARM64 TLB batch unmap、swap entries 批量 unmap、mTHP swap-in、madvise PER_VMA lock 等特质的 author 或 co-author。
参考文献:
[1]slab sheaves和barns
https://lore.kernel.org/linux-mm/20260123-sheaves-for-all-v4-0-041323d506f7@suse.cz/
[2]sched-ext sub-schedulers:
https://lore.kernel.org/lkml/20260121231140.832332-1-tj@kernel.org/
[3]代理奉行Proxy Execution:
https://lwn.net/ml/all/20250712033407.2383110-1-jstultz@google.com/
https://lwn.net/ml/all/20250722070600.3267819-1-jstultz@google.com/
[5]scheduler时分片膨胀:
https://lore.kernel.org/lkml/20251215155615.870031952@linutronix.de/
[6]tcp dmabuf tx零拷贝:
https://lore.kernel.org/netdev/20250508004830.4100853-1-almasrymina@google.com/
[7] io_uring zero_copy rx:
https://lwn.net/Articles/1004591/
[8] io_uring file->dmabuf:
https://lore.kernel.org/all/cover.1763725387.git.asml.silence@gmail.com/
[9]dmem cgroup:
https://lore.kernel.org/lkml/20241204134410.1161769-1-dev@lankhorst.se/
[10]swap table:
https://lore.kernel.org/linux-mm/20250822192023.13477-1-ryncsn@gmail.com/
https://lore.kernel.org/linux-mm/20250514201729.48420-25-ryncsn@gmail.com/
将来莫得前后端,独一 AI Agent 工程师。
这场十倍速的变革已至,你的下一步在哪?
4 月 17-18 日,由 CSDN 与奇点智能商榷院合伙专揽「2026 奇点智能时期大会」将在上海无垠召开,大集聚焦 Agent 系统、宇宙模子、AI 原生研发等 12 大前沿专题,为你绘图通往将来的明白舆图。
成为时期的见证者,更要成为时期的先驱。
奇点智能时期大会上海站,咱们不见不散!














 备案号:
备案号: